Apa itu model bahasa?
Aplikasi AI generatif didukung oleh model bahasa, yang merupakan jenis khusus model pembelajaran mesin yang dapat Anda gunakan untuk melakukan tugas pemrosesan bahasa alami (NLP), termasuk:
- Menentukan sentimen atau mengklasifikasikan teks bahasa alami.
- Meringkas teks.
- Membandingkan beberapa sumber teks untuk kesamaan semantik.
- Menghasilkan bahasa alami baru.
Meskipun prinsip matematika di balik model bahasa ini dapat menjadi kompleks, pemahaman dasar tentang arsitektur yang digunakan untuk mengimplementasikannya dapat membantu Anda mendapatkan pemahaman konseptual tentang cara kerjanya.
Model transformator
Model pembelajaran mesin untuk pemrosesan bahasa alami telah berkembang selama bertahun-tahun. Model bahasa besar mutakhir saat ini didasarkan pada arsitektur transformator, yang dibangun dan memperluas beberapa teknik yang telah terbukti berhasil dalam pemodelan kosakata untuk mendukung tugas NLP - dan khususnya dalam menghasilkan bahasa. Model transformer dilatih dengan teks dalam volume besar, memungkinkannya untuk mewakili hubungan semantik antara kata-kata dan menggunakan hubungan tersebut untuk menentukan kemungkinan urutan teks yang masuk akal. Model transformer dengan kosakata yang cukup besar mampu menghasilkan respons bahasa yang sulit dibedakan dari respons manusia.
Arsitektur model transformer terdiri dari dua komponen, atau blok:
- Blok encoder yang membuat representasi semantik dari kosakata pelatihan.
- Blok dekoder yang menghasilkan urutan bahasa baru.
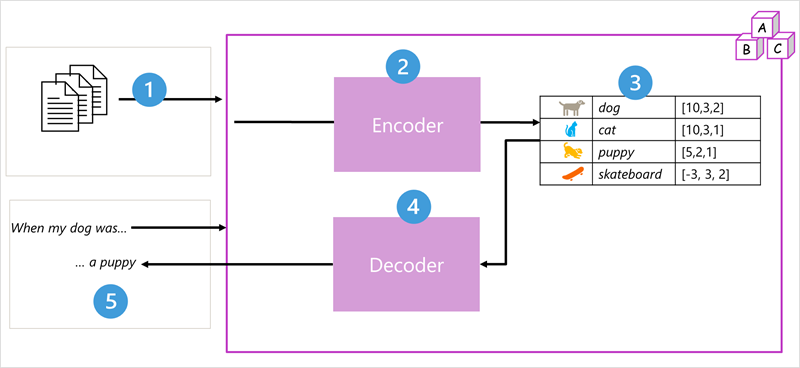
- Model ini dilatih dengan volume besar teks bahasa alami, sering bersumber dari internet atau sumber teks publik lainnya.
- Urutan teks dipecah menjadi token (misalnya, kata-kata individu) dan blok encoder memproses urutan token ini menggunakan teknik yang disebut perhatian untuk menentukan hubungan antara token (misalnya, token mana yang memengaruhi keberadaan token lain secara berurutan, token berbeda yang umumnya digunakan dalam konteks yang sama, dan sebagainya.)
- Output dari encoder adalah kumpulan vektor (array numerik multinilai) di mana setiap elemen vektor mewakili atribut semantik token. Vektor ini disebut sebagai penyematan.
- Blok decoder bekerja pada urutan baru token teks dan menggunakan penyematan yang dihasilkan oleh encoder untuk menghasilkan output bahasa alami yang sesuai.
- Misalnya, mengingat urutan input seperti "Ketika anjing saya berada", model dapat menggunakan teknik perhatian untuk menganalisis token input dan atribut semantik yang dikodekan dalam penyematan untuk memprediksi penyelesaian kalimat yang sesuai, seperti "anak anjing."
Dalam praktiknya, implementasi spesifik arsitektur bervariasi - misalnya, model Representasi Encoder Dua Arah dari Transformer (BERT) yang dikembangkan oleh Google untuk mendukung mesin pencari mereka hanya menggunakan blok encoder, sedangkan model Generative Pretrained Transformer (GPT) yang dikembangkan oleh OpenAI hanya menggunakan blok decoder.
Meskipun penjelasan lengkap tentang setiap aspek model transformer berada di luar cakupan modul ini, penjelasan tentang beberapa elemen kunci dalam transformer dapat membantu Anda memahami bagaimana mereka mendukung AI generatif.
Tokenisasi
Langkah pertama dalam melatih model transformator adalah menguraikan teks pelatihan menjadi token - dengan kata lain, mengidentifikasi setiap nilai teks unik. Demi kesederhanaan, Anda dapat menganggap setiap kata yang berbeda dalam teks pelatihan sebagai token (meskipun pada kenyataannya, token dapat dihasilkan untuk kata-kata parsial, atau kombinasi kata dan tanda baca).
Misalnya, pertimbangkan kalimat berikut:
I heard a dog bark loudly at a cat
Untuk tokenisasi teks ini, Anda dapat mengidentifikasi setiap kata diskrit dan menetapkan ID token kepada mereka. Contohnya:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
Kalimat sekarang dapat diwakili dengan token: {1 2 3 4 5 6 7 3 8}. Demikian pula, kalimat "Saya mendengar kucing" dapat diwakili sebagai {1 2 3 8}.
Saat Anda terus melatih model, setiap token baru dalam teks pelatihan ditambahkan ke kosakata dengan ID token yang sesuai:
- meow (9)
- skateboard (10)
- dan sebagainya...
Dengan serangkaian teks pelatihan yang cukup besar, kosakata ribuan token dapat dikompilasi.
Penyematan
Meskipun mungkin nyaman untuk mewakili token sebagai ID sederhana - pada dasarnya membuat indeks untuk semua kata dalam kosakata, token tidak memberi tahu kita apa-apa tentang arti kata-kata atau hubungan di antara token. Untuk membuat kosakata yang merangkum hubungan semantik antara token, kami menentukan vektor kontekstual, yang dikenal sebagai penyematan untuk kosakata tersebut. Vektor adalah representasi informasi numerik multinilai, misalnya [10, 3, 1] di mana setiap elemen numerik mewakili atribut informasi tertentu. Untuk token bahasa, setiap elemen vektor token mewakili beberapa atribut semantik token. Kategori khusus untuk elemen vektor dalam model bahasa ditentukan selama pelatihan berdasarkan seberapa umum kata-kata digunakan bersama-sama atau dalam konteks yang sama.
Vektor mewakili garis di ruang multidimensi, yang menggambarkan arah dan jarak di sepanjang beberapa sumbu (Anda dapat membuat teman-teman matematika Anda terkesan dengan memanggil amplitudo dan besaran tersebut). Ini dapat berguna untuk memikirkan elemen dalam vektor penyematan untuk token sebagai langkah-langkah yang mewakili di sepanjang jalur di ruang multidimensi. Misalnya, vektor dengan tiga elemen mewakili jalur dalam ruang 3 dimensi yang menjadi ruang untuk nilai elemen tersebut menunjukkan unit yang melakukan perjalanan maju/mundur, kiri/kanan, dan atas/bawah. Secara keseluruhan, vektor menjelaskan arah dan jarak jalur dari asal ke tujuan.
Elemen token dalam ruang penyematan masing-masing mewakili beberapa atribut semantik token, sehingga token yang mirip secara semantik harus menghasilkan vektor yang memiliki orientasi serupa - dengan kata lain mereka menunjuk ke arah yang sama. Teknik yang disebut kesamaan kosinus digunakan untuk menentukan apakah dua vektor memiliki arah yang sama (terlepas dari jarak), dan karenanya mewakili kata-kata yang terkait secara semantik. Sebagai contoh sederhana, misalkan penyematan untuk token kami terdiri dari vektor dengan tiga elemen, misalnya:
- 4 ("anjing"): [10,3,2]
- 8 ("cat"): [10,3,1]
- 9 ("anak anjing"): [5,2,1]
- 10 ("skateboard"): [-3,3,2]
Kita dapat memplot vektor ini dalam ruang tiga dimensi, seperti ini:
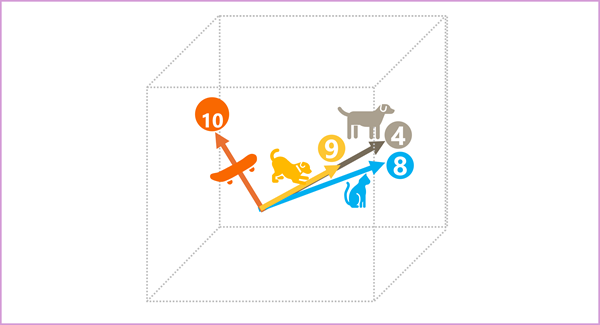
Vektor penyematan untuk anjing" dan "anak anjing" menggambarkan jalur di sepanjang arah yang hampir identik, yang juga cukup mirip dengan arah untuk "kucing". Namun, vektor penyematan untuk "skateboard" menggambarkan perjalanan ke arah yang sangat berbeda.
Catatan
Contoh sebelumnya menunjukkan model contoh sederhana di mana setiap penyematan hanya memiliki tiga dimensi. Model bahasa nyata memiliki lebih banyak dimensi.
Ada beberapa cara untuk menghitung penyematan yang sesuai untuk sekumpulan token tertentu, termasuk algoritma pemodelan bahasa seperti Word2Vec atau blok encoder dalam model transformer.
Perhatian
Blok encoder dan decoder dalam model transformator mencakup beberapa lapisan yang membentuk jaringan neural untuk model. Kita tidak perlu masuk ke detail semua lapisan ini, tetapi berguna untuk mempertimbangkan salah satu jenis lapisan yang digunakan di kedua blok: lapisan perhatian . Perhatian adalah teknik yang digunakan untuk memeriksa urutan token teks dan mencoba mengukur kekuatan hubungan di antara token. Secara khusus, perhatian diri melibatkan mempertimbangkan bagaimana token lain di sekitar satu token tertentu memengaruhi makna token itu.
Dalam blok encoder, setiap token diperiksa dengan cermat dalam konteks, dan pengodean yang sesuai ditentukan untuk penyematan vektornya. Nilai vektor didasarkan pada hubungan antara token dan token lain yang sering muncul. Pendekatan kontekstual ini berarti bahwa kata yang sama mungkin memiliki beberapa penyematan tergantung pada konteks yang digunakannya - misalnya "kulit pohon" berarti sesuatu yang berbeda dengan "Saya mendengar kulit anjing."
Dalam blok decoder, lapisan perhatian digunakan untuk memprediksi token berikutnya secara berurutan. Untuk setiap token yang dihasilkan, model memiliki lapisan perhatian yang memperhitungkan urutan token hingga titik tersebut. Model mempertimbangkan token mana yang paling berpengaruh ketika mempertimbangkan token berikutnya. Misalnya, mengingat urutan "Saya mendengar anjing," lapisan perhatian mungkin menetapkan bobot yang lebih besar ke token "didengar" dan "anjing" ketika mempertimbangkan kata berikutnya dalam urutan:
Aku mendengar anjing [kulit kayu]
Ingatlah bahwa lapisan perhatian bekerja dengan representasi vektor numerik dari token, bukan teks aktual. Dalam dekoder, proses dimulai dengan urutan penyematan token yang mewakili teks yang akan diselesaikan. Hal pertama yang terjadi adalah lapisan pengodean posisi lain menambahkan nilai ke setiap penyematan untuk menunjukkan posisinya dalam urutan:
- [1,5,6,2] (I)
- [2,9,3,1] (didengar)
- [3,1,1,2] (a)
- [4,10,3,2] (anjing)
Selama pelatihan, tujuannya adalah untuk memprediksi vektor untuk token akhir dalam urutan berdasarkan token sebelumnya. Lapisan perhatian menetapkan bobotnumerik untuk setiap token dalam urutan sejauh ini. Lapisan ini menggunakan nilai tersebut untuk melakukan perhitungan pada vektor tertimbang yang menghasilkan skor perhatian yang dapat digunakan untuk menghitung kemungkinan vektor untuk token berikutnya. Dalam praktiknya, teknik yang disebut perhatian multikepala menggunakan elemen penyematan yang berbeda untuk menghitung beberapa skor perhatian. Kemudian jaringan neural digunakan untuk mengevaluasi semua token yang mungkin untuk menentukan token yang paling mungkin untuk melanjutkan urutannya. Proses berlanjut secara berulang untuk setiap token dalam urutan, dengan urutan output sejauh ini digunakan secara regresif sebagai input untuk iterasi berikutnya - pada dasarnya membangun output satu token pada satu waktu.
Animasi berikut menunjukkan representasi yang disederhanakan tentang cara kerjanya - pada kenyataannya, perhitungan yang dilakukan oleh lapisan perhatian lebih kompleks; tetapi prinsip-prinsipnya dapat disederhanakan seperti yang ditunjukkan:

- Urutan penyematan token dimasukkan ke lapisan perhatian. Setiap token direpresentasikan sebagai vektor nilai numerik.
- Tujuan dalam decoder adalah untuk memprediksi token berikutnya dalam urutan, yang juga akan menjadi vektor yang selaras dengan penyematan dalam kosakata model.
- Lapisan perhatian mengevaluasi urutan sejauh ini dan menetapkan bobot ke setiap token untuk mewakili pengaruh relatif token pada token berikutnya.
- Bobot dapat digunakan untuk menghitung vektor baru untuk token berikutnya dengan skor perhatian. Perhatian multikepala menggunakan elemen yang berbeda dalam penyematan untuk menghitung beberapa token alternatif.
- Jaringan neural yang terhubung sepenuhnya menggunakan skor dalam vektor terhitung untuk memprediksi token yang paling mungkin dari seluruh kosakata.
- Output yang diprediksi ditambahkan ke urutan sejauh ini, yang digunakan sebagai input untuk iterasi berikutnya.
Selama pelatihan, urutan token yang sebenarnya diketahui - kami hanya menutupi yang muncul kemudian dalam urutan daripada posisi token yang saat ini sedang dipertimbangkan. Seperti dalam jaringan neural apa pun, nilai yang diprediksi untuk vektor token dibandingkan dengan nilai aktual vektor berikutnya dalam urutan, dan kerugian dihitung. Bobot kemudian disesuaikan secara bertahap untuk mengurangi kehilangan dan meningkatkan model. Ketika digunakan untuk inferensi (memprediksi urutan token baru), lapisan perhatian terlatih menerapkan bobot yang memprediksi token yang paling mungkin dalam kosakata model yang secara semantik selaras dengan urutan sejauh ini.
Arti dari semua ini adalah bahwa model transformer seperti GPT-4 (model di balik ChatGPT dan Bing) dirancang untuk mengambil input teks (disebut perintah) dan menghasilkan output yang benar secara sintetis (disebut penyelesaian). Akibatnya, "keajaiban" model adalah bahwa model memiliki kemampuan untuk meringkas kalimat yang koheren bersama-sama. Kemampuan ini tidak menyiratkan "pengetahuan" atau "kecerdasan" pada bagian model; hanya kosakata besar dan kemampuan untuk menghasilkan urutan kata yang bermakna. Namun, apa yang membuat model bahasa besar seperti GPT-4 begitu kuat adalah volume data tipis yang telah dilatih (data publik dan berlisensi dari Internet) dan kompleksitas jaringan. Hal ini memungkinkan model untuk menghasilkan penyelesaian yang didasarkan pada hubungan antara kata-kata dalam kosakata tempat model dilatih; sering menghasilkan output yang tidak dapat dibedakan dari respons manusia ke perintah yang sama.